

 会员登录
会员登录
微软发布OmniParser V2,让大语言模型秒变“电脑操作高手”,亲测有效!
2025年2月12日,微软团队推出了一项名为 OmniParser V2 的技术升级。这项工具能够将任何大型语言模型(LLM)转化为一个具备计算机操作能力的智能代理(Computer Use Agent)。
模型:https://huggingface.co/microsoft/OmniParser-v2.0
发布博客:OmniParser V2: Turning Any LLM into a Computer Use Agent - Microsoft Research
Demo:https://huggingface.co/spaces/microsoft/OmniParser-v2
代码:GitHub - microsoft/OmniParser: A simple screen parsing tool towards pure vision based GUI agent
OmniParser V2 的核心功能
图形用户界面(GUI)自动化需要智能代理能够理解并交互用户屏幕上的内容。然而,直接使用通用型大语言模型作为 GUI 代理存在两大挑战:
准确识别用户界面上可交互的图标;
理解屏幕截图中各种元素的语义,并将预期的操作与屏幕上的对应区域精准关联。
为了解决这些问题,OmniParser 提出了创新性的解决方案:将用户界面的像素空间“分词化”,将其转化为结构化的、可被大语言模型理解的元素。这使得 LLM 能够基于解析出的可交互元素进行下一步操作预测。而 OmniParser V2 在其前代基础上进一步提升了性能,特别是在检测较小的可交互元素时表现出更高的准确性,同时显著加快了推理速度,使其成为 GUI 自动化的强大工具。
具体而言,OmniParser V2 使用了更大规模的交互元素检测数据集和图标功能描述数据进行训练。通过优化图标描述模型的图像尺寸,新版本的延迟减少了 60%。值得一提的是,结合 GPT-4o 使用时,OmniParser V2 在最新发布的高分辨率屏幕基准测试 ScreenSpot Pro 上达到了 39.6 的平均准确率,这一成绩远超 GPT-4o 原始得分(0.8),堪称当前最先进的表现。
OmniTool 的引入
为了加速不同代理设置的实验,研究团队还开发了 OmniTool ,这是一个容器化的 Windows 系统,内置了一系列支持智能代理运行的核心工具。开箱即用,OmniTool 支持多种前沿的大语言模型,包括 OpenAI(4o/o1/o3-mini)、DeepSeek(R1)、通义千问(Qwen 2.5VL)和 Anthropic(Sonnet)。这些模型可以无缝整合屏幕理解、定位、动作规划和执行等步骤,从而实现高效的自动化任务。
风险与缓解措施
为了符合微软的人工智能原则和负责任的人工智能实践,研究团队采取了一系列风险缓解措施。例如,在训练图标描述模型时,使用了专门设计的“负责任 AI 数据”,以尽量避免模型从图标图像中推断敏感属性(如种族、宗教等)。此外,研究团队建议用户仅对不包含有害内容的屏幕截图使用 OmniParser。对于 OmniTool,团队利用微软威胁建模工具进行了全面的安全性分析,并在 GitHub 仓库中提供了沙盒 Docker 容器、安全指南和示例代码。最后,团队强调在使用过程中应保持人类监督,以最大限度地降低潜在风险。
模型说明:
OmniParser V2发布后迅速引起大家关注,在Huggingface的Trending榜上排名第3
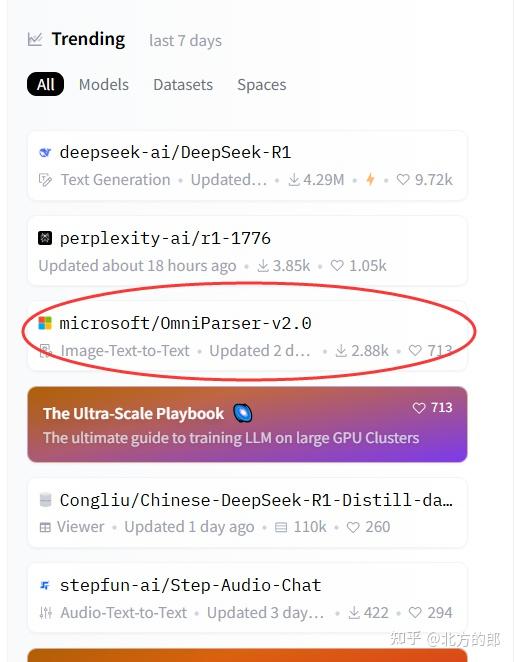
模型概述
OmniParser 是一款通用的屏幕解析工具,能够将用户界面(UI)截图转换为结构化格式,从而提升现有的基于大语言模型(LLM)的 UI 代理能力。训练数据集包括:
可交互图标检测数据集 :从热门网页中收集并自动标注,突出显示可点击和可操作区域;
图标描述数据集 :旨在将每个 UI 元素与其对应的功能相关联。
该模型中心包含两个微调版本的模型:一个是基于 YOLOv8 的微调版本,另一个是基于 Florence-2 基础模型的微调版本。
V2 版本新增内容
更大、更干净的图标描述与定位数据集
相比 V1 版本,延迟性能提升了 60% :A100 上平均延迟为 0.6 秒/帧 ,单张 4090 显卡上为 0.8 秒/帧 。
出色性能:在 ScreenSpot Pro 数据集上达到 39.6 的平均准确率 。
您的智能代理只需要一个工具:OmniTool !通过 OmniParser 和您选择的视觉模型,即可控制一台 Windows 11 虚拟机。OmniTool 开箱即用,支持以下大语言模型:OpenAI(4o/o1/o3-mini)、DeepSeek(R1)、通义千问(Qwen 2.5VL)或 Anthropic Computer Use。详情请查看我们的 GitHub 仓库。
预期用途
OmniParser 的设计目标是将非结构化的屏幕截图转化为结构化的元素列表,包括可交互区域的位置以及图标功能的描述性文本。
OmniParser 适用于那些已经接受过负责任分析方法培训,并具备批判性思维能力的用户。虽然 OmniParser 可以从截图中提取信息,但其输出仍需人类判断来确保准确性。
OmniParser 可用于各种设备(如 PC 和手机)以及各类应用程序的屏幕截图解析。
局限性
OmniParser 的设计目标是忠实地将屏幕截图转化为可交互区域的结构化元素和屏幕语义信息,但它不会检测输入中的有害内容(因为用户可以自由决定提供给任何 LLM 的输入)。因此,用户应确保提供给 OmniParser 的输入不包含有害内容。
尽管 OmniParser 仅将屏幕截图转化为文本,但它可以被用来构建基于 LLM 的可操作 GUI 代理。在使用 OmniParser 开发和运行代理时,开发者需要承担责任并遵循常见的安全标准。
许可协议
请注意,icon_detect 模型采用 AGPL 许可协议,而 icon_caption 模型采用 MIT 许可协议。具体许可条款请参考各模型文件夹中的 LICENSE 文件。
简单测试:
直接使用Demo:https://huggingface.co/spaces/microsoft/OmniParser-v2
信息提取
直接输入https://github.com/microsoft/OmniParser/tree/master的截图。
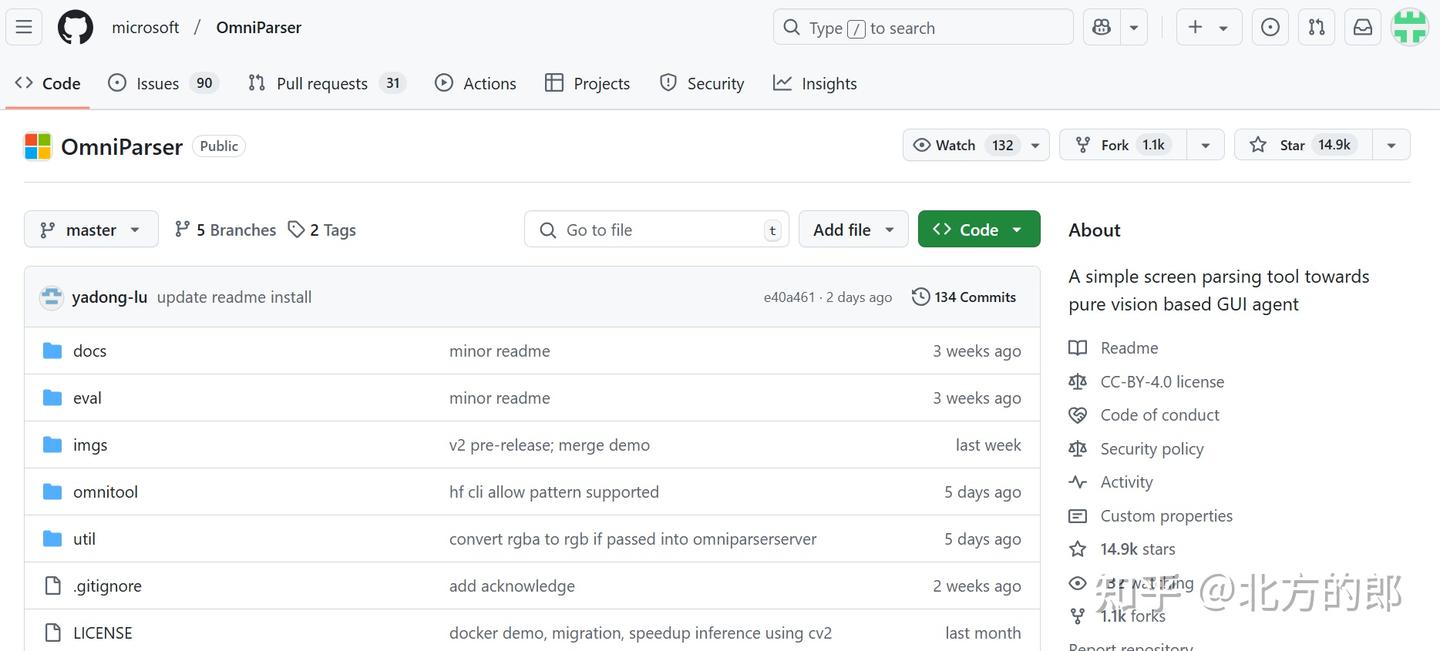
分析结果:

识别的很准确,那么这些信息大模型能用起来么?于是我将Prompt:
以下内容是GUI分析工具OmniParser对一个GitHub页面的分析结果。我现在要下载代码,需要进行什么操作?
icon 0: {'type': 'text', 'bbox': [0.07601713389158249, 0.02248520776629448, 0.21145610511302948, 0.06035503000020981], 'interactivity': False, 'content': 'microsoft / OmniParser'}
icon 1: {'type': 'text', 'bbox': [0.5396145582199097, 0.020118342712521553, 0.6520342826843262, 0.06508875638246536], 'interactivity': False, 'content': 'Q Type to search'}
..........
分别发给当今最强大的大模型: OpenAI ChatGPT, DeepSeek-R1和Grok3进行测试。
ChatGPT(未选推理)
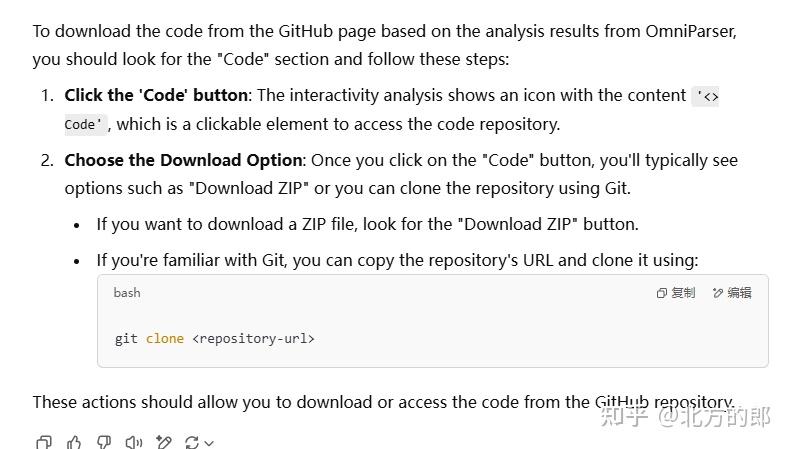
这个虽然提示用Code下载,不过没有说具体的位置。
ChatGPT(选择推理)
这次的符合要求
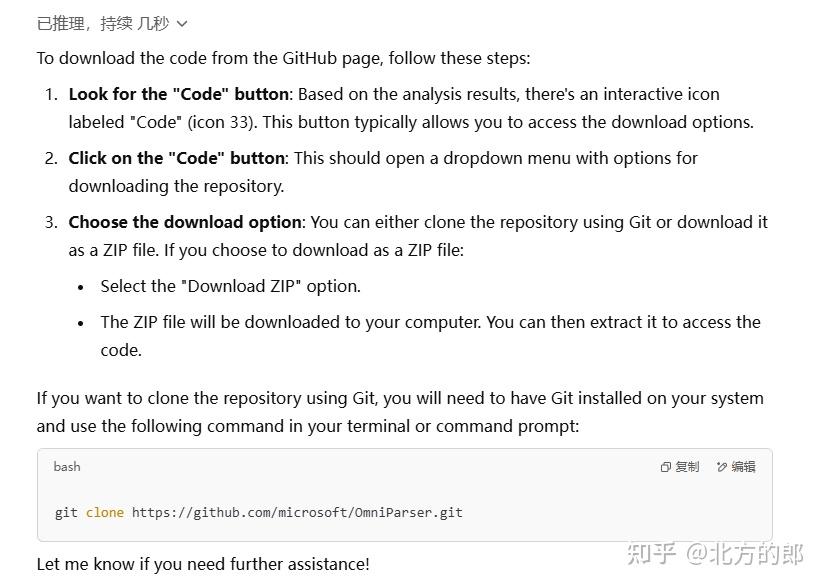
Grok 3(选择思考)
经过非常长的思考,最终给出正确答案:

DeepSeek-R1
DeepSeek-R1也是正确的。

DeepSeek-V3
不选择“深度思考”,DeepSeek-V3也是正确的。

通过测试表明OmniParser V2信息提取非常准确,可以作为构建GUI智能体的“眼睛”,配合能力强大的LLM,可以实现非常复杂的操作。
——完——
 |
 |
 |
 |
 |
 |
 |
 |
| 感动 | 同情 | 无聊 | 愤怒 | 搞笑 | 难过 | 高兴 | 路过 |
相关文章
-
没有相关内容