

 会员登录
会员登录
微软开源Phi-4推理模型:啰嗦AI,反卷出圈

AI圈子最有意思的事,已经不是“谁家模型参数最多”,而是——谁家小模型,能把大模型打趴下。
最近,微软研究院开源了一款“小而强”的研究:Phi-4-reasoning-plus。这是一款专为深度结构化推理任务设计的开源语言模型。
14B参数,不到DeepSeek 70B的五分之一,但数学、科学、代码、逻辑推理的表现,都比较能打。
在AIME 2025数学考试上,14B的小模型,第一次尝试的全题正确率,居然干过了70B的精炼大块头,甚至快摸到DeepSeek 671B的脚后跟。
微软团队用一串“推理链”打破了常规,让AI学会慢下来、啰嗦一点、反复琢 磨、允许自己犯错,主要体现在:
推理链(Chain-of-Thought)成为核心训练目标 。不是像传统大模型那样直接给出答案,而是专门训练模型写“推理过程”;在训练数据和输出里,强制要求模型用<think>...</think>标签,把自己的思考、分步推理、反复验证详细写出来。这种推理链往往很“啰嗦”:不是一句话解决问题,而是像人类一样,细致分解、逐步排查。
鼓励“慢思考”,奖励啰嗦的推理过程。 在RL(强化学习)阶段,奖励机制被专门设计成:答错时鼓励更长推理链,答对时鼓励简洁;只要模型没答对,就鼓励它“多想两步”,推理过程可以更长、更详细,甚至反复自我否定和修正。
结果?不仅答案对,思路也清晰。

技术报告里有个细节特别有意思:Phi-4-reasoning的推理链,不是越长越好,也不是越短越强,而是“刚刚好”地模拟了人类的“思考长度”。
RL阶段的奖励模式具体是:“答对了要简洁,答错了反而鼓励多思考”,而有些任务,答题过程还会“自我否定”,甚至推翻重来。当然,不是所有领域都大幅提升,比如生物、化学、离散数学,AI也会“卡壳”。
Phi-4-reasoning-plus在SFT(有监督微调)之后,还加了一层 基于规则的强化学习 ,奖励设计也很精妙:
答对了鼓励简洁(奖励简短推理)
答错了反而鼓励啰嗦(奖励多想一步)
输出格式不对、思路紊乱要扣分
重复语句有惩罚,鼓励多样性和探索
这和传统RLHF(基于人类反馈强化学习)不同,Phi-4团队用的是可自动验证的数学题,奖励函数直接和推理链长度、答案正确性挂钩,模型被训练成“有错就多想、多写,多步反省”。
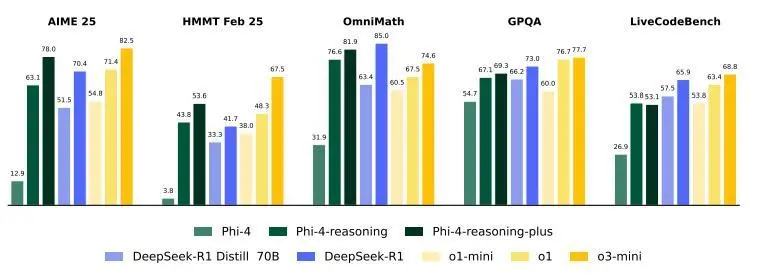
Phi-4推理模型在跨领域基准测试中的表现
报告里的评测结果,Phi-4-reasoning和plus不仅在AIME、OmniMath、GPQA等数学/科学基准上干翻了体量更大的Distill-Llama-70B、DeepSeek-R1,甚至在算法(TSP/3SAT)、规划(BA-Calendar)、代码(LiveCodeBench)等新领域也展现了极强的“迁移力”,而这些领域,模型训练时根本没专门覆盖。
这就是推理链带来的元能力:模型不仅会解题,更会“怎么推理”,新题型也能举一反三,遇到没见过的难题也能慢慢推、反复试。对比传统大模型“一步到位”的完美答案,这种“磨叽”的AI反而更靠谱、更有韧性。
甚至在一些“非推理”任务,如长文本问答、指令遵循、毒性检测等通用能力测试中,Phi-4-reasoning-plus也有显著提升。归根结底,让AI学会慢思考、会自我检视,比单纯提升算力和知识面更可持续。
 |
 |
 |
 |
 |
 |
 |
 |
| 感动 | 同情 | 无聊 | 愤怒 | 搞笑 | 难过 | 高兴 | 路过 |
相关文章
-
没有相关内容